对数据进行KMeans聚类分析并可视化聚类结果 亲测能成功跑出来的KMeans算法代码
”kmeans 聚类 算法 机器学习 人工智能“ 的搜索结果
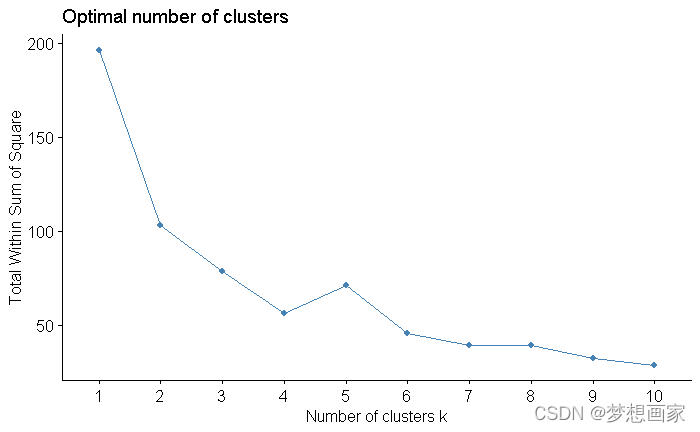
Kmeans聚类算法-手肘法,jupyter notebook 编写,打开可以直接运行,使用iris等5个数据集,机器学习。
无监督学习-kmeans聚类算法及手动实现jupyter代码.ipynb
实验报告——Kmeans聚类方法.docx

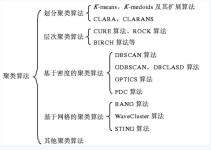
一、聚类简介是常见的unsupervised learning (无监督学习)方法,简单地说就是把相似的数据样本分到一组(簇),聚类的过程,我们并不清楚某一类是什么(通常...深度聚类方法主要是根据表征学习后的特征+传统聚类算法。

机器学习算法 机器学习算法之KMeans聚类算法实现
KMEANS聚类算法的MATLAB代码 Algorithm 用Python,Matlab写的一些算法 \ (主目录) 文件名:算法名_功能 DeepLearning 来自吴恩达的深度学习课程 IntelligentAlgorithm 智能算法的代码 粒子群 模拟退火 鱼群算法 ...
如果相同,结束聚类,算法收敛。 如果不相同:把这3个平均值当做新的中心点,从第二步开始重新开始。 1.2 k-means算法的评估标准 外部距离最大化,内部距离最小化。 1、计算蓝1到自身类别的点距离的平均值a_i...

Kmeans是一种无监督的基于距离的聚类算法,其变种还有Kmeans++。其中,sklearn中KMeans的默认使用的即为KMeans++。。本文主要通过纯手写的方式,帮助学习理解KMeans算法的数据处理过程。
。。。
。。。
K-means算法是最常用的一种聚类算法。算法的输入为一个样本集(或者称为点集),通过该算法可以将样本进行聚类,具有相似特征的样本聚为一类。针对每个点,计算这个点距离所有中心点最近的那个中心点,然后将这个点...

本文实例讲述了Python实现的KMeans聚类算法。分享给大家供大家参考,具体如下: 菜鸟一枚,编程初学者,最近想使用Python3实现几个简单的机器学习分析方法,记录一下自己的学习过程。 关于KMeans算法本身就不做介绍...
K-means算法是一种常用的聚类算法,用于将数据集划分成k个不重叠的簇。其主要思想是通过迭代的方式将样本点划分到不同的簇中,使得同一簇内的样本点相似度较高,不同簇之间的相似度较低。
。。。
。。。


对给定的数据集进行聚类 本案例采用二维数据集,共80个样本,有4个类。样例如下(testSet.txt): 1.658985 4.285136 -3.453687 3.424321 4.838138 -1.151539 -5.379713 -3.362104 0.972564 2.924086 -3.567919 1...

matlab实现Kmeans聚类算法+过程、结果可视化
sklearn学习中所需要的聚类算法解析,文档中主要解析了kmeans算法用法

KMeans 聚类算法是一种基于距离的聚类算法,用于将数据点分成若干组。在 Python 中,可以使用 scikit-learn 库中的 KMeans 函数来实现 KMeans 聚类算法。 以下是一个 Python 实现 KMeans 聚类算法的示例: from ...
推荐文章
- AndroidStudio4.1 自定义模板_android studio 4.1 自定义模板-程序员宅基地
- 微信小程序云开发-酒店点餐类系统,附带(node.js在widows环境下的配置过程)_云开发可以做扫码类么-程序员宅基地
- jq使用ajax报错404,jQuery中ajax错误调试分析-程序员宅基地
- HDU 1587 Flowers 解题报告_2019 flowers acm-程序员宅基地
- 沉云架路,边缘先锋—中国联通5G边缘先锋团队2020年交付纪实-程序员宅基地
- Web性能优化:图片优化-程序员宅基地
- openGauss 向量化引擎-程序员宅基地
- 云锁linux宝塔安装,【最新版】宝塔面板下为Nginx自编译云锁Web防护模块教程-程序员宅基地
- Android 笔记:Error:A problem occurred configuring project ':app'.-程序员宅基地
- dataframe的groupby,agg,unstack应用_group by unstack-程序员宅基地